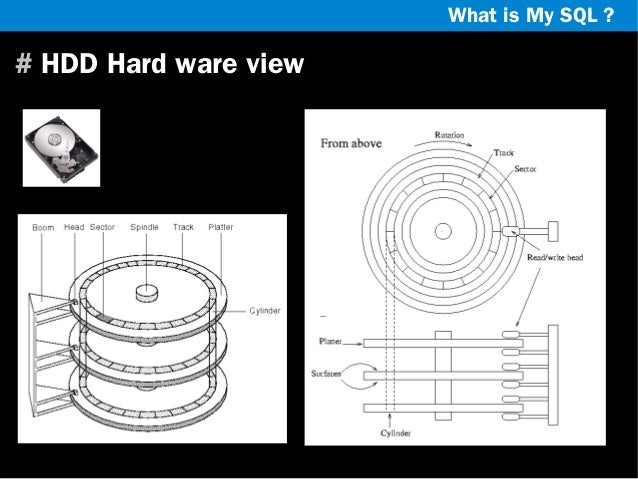
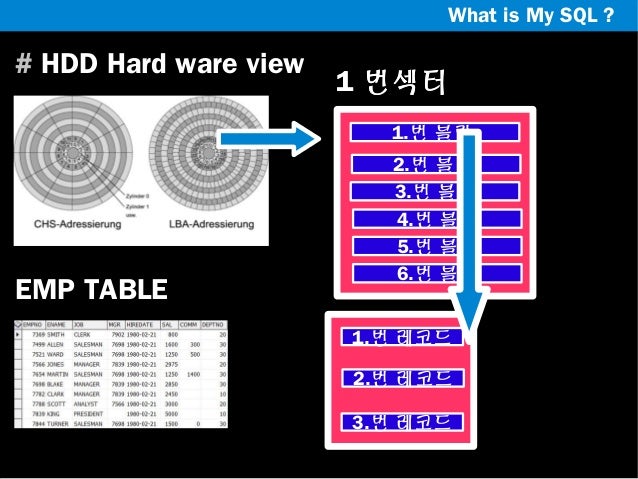
∴ Embedded System에 적합한 프로세서 구조는? RISC : 로드-스토어(Load-Store) 아키텍처 프로세서는 보통 레지스터 안에 저장되어 있는 데이터를 이용하여 어떤 동작을 수행한다. 메모리에서 레지스터로 데이터를 읽어들일 때에는 로드 명령어를, 레지스터에서 메모리로 데이터를 저장할 때에는 스토어 명령어를 사용한다. 메모리를 액세스하기 위해서는 비용이 들기 때문에, 메모리를 여러 번 액세스하는 대신, 레지스터 안에 저장되어 있는 데이터를 여러 번 사용하는 식으로, 데이터 처리 동작과 메모리 액세스를 분리하는 것이 좋다.
: CISC는 하드웨어의 복잡도에 초점을 맞추고 있고, RISC는 컴파일러의 복잡도에 초점을 맞추고 있다.
: 이러한 설계 방식은 RISC 프로세서를 더욱 단순화시켜, 결론적으로 더 빠른 클럭으로 동작할 수 있게 되었다. 반면 전형적인 CISC 프로세서는 좀더 복잡하고, 좀더 낮은 클럭으로 동작한다. 하지만 지난 20년 동안, CISC가 RISC의 개념을 조금씩 적용함에 따라, RISC와 CISC 사이의 구분이 점점 모호해지고 있다.
■ 레지스터
■ 연산 장치 (ALU: Arithmetic & Logic Unit) ■ 제어 장치 (CU: Control Unit)
■ 버스 (Bus)
- 메모리
: 프로그램과 데이터를 저장하기 위한 공간
■ 주기억 장치 : 프로그램이 실행되는 동안 프로그램과 데이터 저장 : DRAM이 주로 사용
■ 보조 기억 장치 : 주기억 장치보다 빈번하게 사용되지 않는 프로그램과 데이터 저장 : HDD, SD, MMC ■ Cache : 주기억 장치의 접근 속도를 빠르게 하기 위해서 프로세서 주변에 배치된 소용량의 메모리 : 프로세서가 읽고자 하는 명령이나 데이터를 최대한 빨리 프로세서에 전달하는데 목적 : Data Inconsistency 발생 가능 : SRAM이 주로 사용
■ Flash Memory
- 입/출력 장치
■ Interrupt : Interrupt Latency? Interrupt가 발생했을 때부터 프로세서가 관련 ISR을 수행하기 시작할 때까지 걸린 시간 : Interrupt Nesting? Interrupt는 비동기 이벤트이기 때문에 여러 개의 Interrupt가 동시에 발생할 수 있음, 모든 Interrupt에 대해 우선 순위를 정의해두고 높은 순위를 가지는 Interrupt를 낮은 순위의 Interrupt보다 우선적으로 처리
■ DMA (Direct Memory Access) : 같은 Bus를 사용할 경우 충돌 가능성
■ UART (A Universal Asynchronous Receiver/Transmitter)
■ GPIO (General Purpose I/O)
- System Bus : Bus Handshaking : Wait Signals : Wait States ■ Architecture[폰-노이만(Von-Neumann) vs 하버드(Harvard Architecture)]
Datalink Layer Service : 오류 검출 및 정정 : 브로드캐스트 채널 공유 : 다중 접속 : 링크 계층 주소체계 : 근거리 네트워크(LAN) - 이더넷, VLAN : 경로 상의 각 링크에서 서로 다른 링크 계층 프로토콜로 데이터그램 전송, 각 링크 프로토콜은 서로 다른 서비스 제공
오류 검출 및 정정 기술 - EDC(Error Detection and Correction) - 패리티 검사 - 인터넷 체크섬 - 순환중복검사(CRC: Cyclic Redundancy Check)
다중 접속 프로토콜 (Multiple Access Protocol, MAC protocol)
: 둘 이상의 노드가 동시에 전송하면 충돌이 발생 - 채널 분할 프로토콜(channel partition protocol) : 채널을 더 작은 "조각"들로 분할(시간 슬롯, 주파수, 코드) : 할당된 조각들은 노드가 배타적으로 사용 : 높은 부하에서는 효율적이고 공정하게 채널 공유 : 낮은 부하에서는 비효율적(하나의 활성 노드에 대해서도 1/N 대역폭 할당) : TDMA(Time Division Multiple Access), FDMA(Frequency Division Multiple Access), CDMA(Code Division Multiple Access) - 랜덤 접속 프로토콜(random access protocol) : 채널은 분할하지 않고 충돌 허용 : 충돌 시 복구 : 낮은 부하에서는 효율적(단일 노드가 전체 채널 대역폭 사용 : 높은 부하에서는 충돌 오버헤드 : 캐리어 센싱(유선에서는 감지 쉽지만, 무선에서는 어려움) : 이더넷에서 적용된 CSMA/CD, 802.11에 적용된 CSMA/CA : 알로하(ALOHA), 슬롯 알로하(S-ALOHA, slotted ALOHA), CSMA(Carrier Sense Multiple Access), CSMA/CD(Collison Detection), CSMA/CA
- 순번 프로토콜(taking turns protocol) : 노드가 순번대로 채널을 사용 : 더 많은 데이터를 전송하는 노드는 오랫동안 순번을 기다려야 함 : 두 가지의 장점을 취함 : 폴링, 토큰 전달 : 블루투스, FDDI(Fiber Distributed Data Interface)
근거리 네트워크(LAN)
- MAC 주소
- ARP(Address Resolution Protocol) ■ 같은 LAN ■ 다른 LAN으로 라우팅
이더넷 : 오늘날 가장 많이 사용되는 LAN 기술 : 가격 저렴 : 토큰 LAN이나 ATM보다 더 싸고 간단 : 빠른 속도 : 1990년대 중반까지 버스 토폴로지 형태를 사용하다가 오늘날은 중앙에 스위치를 둔 스타 토폴로지 사용(노드간의 충돌이 없음)
Network Layer : transport segment를 발신 호스트에서 수신 호스트까지 보냄 : sending side는 transport layer에서 segment를 받아 datagrams을 캡슐화 : receiving side는 transport layer로 datagrams에서 segment를 추출하여 전달 : 모든 호스트와 라우터에 network layer protocols 내장 : 라우터는 입력 링크의 IP datagrams의 헤더 필드를 조사하여 출력 링크로 전달
네트워크 계층의 연결형 및 비연결형 서비스 - 데이터그램 네트워크(datagram network)는 네트워크 계층에서 비연결형 서비스만 제공 - 가상회선 네트워크(virtual circuit network)는 네트워크 계층에서 연결형 서비스만을 제공 - 트랜스포트 계층 서비스와 유사하지만 네트워크 계층 서비스는 다음과 같은 차이 : 호스트 사이의 서비스 : 연결형이나 비연결형 서비스 하나만 제공 : 종단 뿐만 아니라 네트워크 코어의 라우터에서도 구현
Two Key Network-Layer Functions - Forwarding : 라우터의 입력 포트에서 출력 포트로 패킷을 이동시키는 것 : 한 교차로를 지나가는 과정 : 32비트 IP 주소는 40억개 이상의 주소를 가지므로 라우터 포워딩 테이블이 목적지 주소마다 하나의 엔트리를 갖는다면 아주 큰 테이블이 필요
- Routing : 패킷의 출발지에서 목적지까지의 경로를 얻어내는 것 : 출발지에서 목적지까지 여행을 계획하는 과정 ■ 라우팅 알고리즘 : 링크 상태 라우팅 알고리즘
: 거리 벡터 라우팅 알고리즘
: 계층적인 라우팅 : 모든 라우터가 동일, 하나의 네트워크로 이상적인 환경으로 가정했지만, 실제는 6억개 이상의 호스트로 인해 확장이 어렵고, 여러 조직의 네트워크가 존재하여 관리 자치권부여에 어려움음 겪음
Router Architecture Overview
- Two key router functions : 라우팅 알고리즘/ 프로토콜 수행(RIP, OSPF, BGP) : 입력 링크를 출력 링크로 포워딩 - Input Port Functions
- Switching Fabric : memory? 1 세대 라우터, 메모리 대역폭에 따라 속도 제한 : bus? 버스의 대역폭에 따라 스위칭 속도 제한 : crossbar? 버스의 대역폭 한계를 극복 - Output Port Functions
IP: Internet Protocol - 호스트, 라우터의 네트워크 계층 기능
- IP datagram format - IP 단편화와 재결합 - IPv4 addressing ■ Subnet
■ CIDR(Classless Interdomain Routing) : /23, 상위 23비트가 서브넷 주소
■ DHCP(Dynamic Host Configuration Protocol) : 호스트가 네트워크에 접속할 때 서버로부터 IP 주소를 동적으로 획득 : 네트워크에 연결되었을 때만 주소를 가지므로 주소의 재사용 가능 : 짧은 시간 동안에 네트워크에 연결되는 모바일 사용자 지원 : 플러그 앤 플레이 (plug-and-play) 프로토콜 : 할당된 서브넷 IP 주소 외에 첫 번째 홉 라우터의 주소, DNS 서버의 이름과 IP 주소, 네트워크 마스크 (주소에서 네트워크 호스트의 부분을 표시)
■ ICANN(Internet Corporation for Assigned Names and Numbers) : ISP가 주소 블록을 획득받는 곳 : [RFC 2050]을 기반으로 IP주소 할당 : DNS 관리, 도메인 이름을 할당하고, 도메인 이름 분쟁 해결
■ NAT(Network Address Translation) : 지역 네트워크는 외부 세계에로는 하나의 IP 주소만을 사용 : 모든 디바이스에 대해 하나의 IP 주소만을 사용하여, ISP로 부터 여러 개 주소를 할당 받을 필요 없고, 디바이스의 주소를 변경하지 않고 ISP를 바꿀 수 있음 : 지역 네트워크 내부의 디바이스들은 외부 세계에서 명시적으로 주소지정을 하거나 노출되지 않음 (보안 이점) : 16 비트 포트번호 단일 LAN 측 주소로 6만개 동시 연결 : 포트번호는 호스트 주소 지정이 아닌 프로세스 주소 지정에 사용되어야 함 : 라우터는 계층 3까지만 처리해야 함 : 종단 간의 논의에 위반, 호스트가 IP 주소와 포트번호 수정 없이 직접 통신해야 함 : 주소의 부족은 IPv6로 해결 : 횡단 문제 해결로 정적 구성, UPnP, 릴레이
- ICMP(Internet Control Message Protocol) : ICMP는 호스트와 라우터 사이에서 네트워크 계층 정보를 통신하기 위해 사용 (오류 보고, 반향 요청/응답) : IP 상위 계층으로 ICMP 메세지는 IP 데이터그램의 페이로드로 전송
- IPv6 : 32 비트 IP 주소 공간이 빠른 속도로 고갈로 인한 등장 : 빠른 처리와 포워딩을 지원하는 헤더 포맷, QoS가 용이한 헤더 ■ IPv6 datagram format : 고정된 길이의 40바이트 헤더 : 단편화(fragmentation)를 허용하지 않음 : 2128 개로 거의 무한대에 가까운 주소 갯수
- IPv4 vs IPv6 : 체크섬 제거 -> 각 홉에서의 처리 시간 줄임 : 옵션 제거 -> 더 이상 표준 IP 헤더 필드가 아닌 IPv6 헤더의 '다음 헤더' 중 하나가 될 수는 있음 : ICMPv6 -> ICMP의 새로운 버전으로 추가적인 메시지 타입, 코드, 멀티 캐스트 그룹 관리 기능 추가 : IPv4 -> IPv6로의 전환? 모든 라우터들을 동시에 업그레이드 할 수 없음 -> 터널링을 통해 해결 ■ 터널링
Routing in the Internet : 내부 게이트웨이 프로토콜(Interior Gateway Protocols, IGP) - RIP : 라우팅 정보 프로토콜(Routing Information Protocol) : 거리 측정 (비용 측정) - 홉(hop)의 수, 최대 홉은 15로 제한, 각 링크 비용은 1 : RIP 라우팅 테이블은 routed(데몬)라는 애플리케이션 계층 프로세스로 구현, 광고는 UDP 패킷으로 주기적으로 반복 전송
- OSPF : 개방형 최단경로 우선(Open Shortest Path First) : "open"은 라우팅 프로토콜이 공용으로 사용 가능함을 의미, RIP는 주로 하위 계층 ISP나 기업 네트워크 구축에 사용되는 반면, OPSF는 상위 계층 ISP들이 사용 : 링크 상태의 다익스트라 최소비용경로 알고리즘, 각 노드는 전체 AS의 토폴로지 맵을 가짐 : OSPF 광고는 인접한 라우터뿐만 아니라 모든 라우터에 라우팅 정보를 브로드캐스트, 링크 상태 정보를 플러딩, TCP나 UDP가 아닌 IP 상에서 직접 OSPF 메시지를 전송 : RIP에 없는 특징으로 보안, 여러 동일 비용 경로, 여러 비용 측정값, 유니캐스트와 멀티캐스트 통합 지원, 단일 라우팅 도메인에서의 계층 지원 - IGRP : 내부 게이트웨이 라우팅 프로토콜(Interior Gateway Roution Protocol, IGRP), Cisco사 전용
- BGP : 사실상의 인터넷 표준인 인터-AS 라우팅 프로토콜, Border Gateway Protocol : 각 AS에게 이웃들로부터 서브넷 도달성 정보, AS 내부의 모든 라우터에게 도달성 정보 전파, 도달성 정보와 AS정책에 근거하여 서브넷으로의 '좋은' 경로 결정 : 각 서브넷이 자신의 존재를 외부 네트워크로 광고 하도록 함 "I am here" : TCP를 사용하여 BGP 메세지 교환 (OPEN, UPDATE, KEEPALIVE, NOTOFICATION)
Transport services and protocols : 서로 다른 호스트의 프로세스간 논리적인 연결 제공 : 종단 시스템 간에 동작하는 첫번째 layer : send side에서 app msg를 segment로 쪼개 network layer로 전송 : receive side에서는 segment를 message로 재조립하여 application layer로 전송
- Transport vs. Network layer : Transport는 프로세스간 논리적인 연결 : Network는 호스트간 논리적인 연결
TCP vs. UDP : 두 프로토콜 모두 delay, bandwidth guarantees 이용 불가 : 많은 application들은 하나의 transport layer protocol을 사용하므로 Multiplexing and Demultiplexing이 필요함
- TCP(Transmission Control Protocol) : 신뢰성, 메세지 순서 보장 : 연결성(발신자 수신자간 handshaking) : point-to-point : full duplex (전이중 방식), 하나의 Connection에서 양쪽으로 데이터 흐름 : 혼잡 제어, pipelined(window size로 혼잡 및 흐름 제어) : send & receive buffers : HTTP, FTP, SMTP, Telnet 등에 사용
TCP segment structure
■ 3-hand-shaking
■ 4-hand-shaking
- UDP(User Datagram Protocol) : 비신뢰성, 메세지 비순서 : 비연결성(발신자와 수신자간의 handshaking 없이 port만으로 소켓 구별, no-frills extension of “best-effort” IP) : 설계방식에 따라 full duplex, half duplex (반이중 방식) : reliability를 application layer상에 추가(RUDP)할 수 있지만 app-specific error만 복구 가능 : RTT가 너무 짧으면 불필요한 재전송 발생, RTT가 너무 길면 느린 reaction과 segment 손실 가능성 : RIP(Routing Information Protocol), DNS, NFS(Network File System), SNMP(Simple Network Management Protocol)등에 사용
UDP segment structure
■ Checksum : segment의 에러 체크 : header + data + pseudo-header의 sum의 16 bit-one's complement 값 : 모든 Data값과 checksum값을 더했을 때 모든 bit가 1로 채워져있다면 에러가 없음을 의미, 에러가 검출되면 해당 segment는 버려짐
Multiplexing and Demultiplexing
- Demultiplexing : host는 IP datagrams을 받음(IP와 PORT로 적합한 소켓을 구별) : 각 datagram은 source IP address, destination IP address를 가짐 : 각 datagram은 1 transport-layer segment를 가짐 : 각 segment는 source, destination port를 가짐
1. Connectionless demultiplexing
2. Connection-oriented demultiplexing
Principles of Reliable data transfer(RDT) : FSM(Finite State Machine)? 각각 loop를 돌고 있는 상태 : ACKs(ACKnowledgements)? 수신자가 패킷을 받았다고 발신자에게 보내는 신호 : NAKs(Negative ACKnowledgements)? 수신자가 패킷에 에러가 있다고 발신자에게 보내는 신호(seq# ack로 대체) : rdt 1.0? 수신, 발신 FSM을 분리 -> rdt 2.0? 에러 복구에 대한 ACK, NAK 도입 -> ACK/NAK 에러 발생시 발신자는 알수없으므로 중복 전송 가능성 -> rdt 2.1? 발신자는 ACK/NAK를 받았을 경우에만 재전송, 각 패킷에 sequence number를 붙임, 수신자는 중복 패킷 버림 (stop and wait) -> ACK/NAK에서 에러가 발생할 경우 전송한 패킷을 재전송 가능성 -> rdt 2.2? NAK 대신 마지막으로 받은 패킷의 seq를 ACK에 붙여 전송 -> 패킷이나 ACK에서 에러나 손실이 발생하면 무한정 기다리게 됨 ->rdt 3.0? time-out 도입
1. Forward Error Correction(FEC) : Realtime communication : 수신자로 하여금 에러를 수정할 수 있도록 redundant bits를 추가 2. Retransmission : 수신자가 에러를 감지하고 발신자에게 data를 다시 전송해달라고 요청 : ARQ(Automatic Repeat reQuest) : 수신자 피드백 방식, 오류검출만으로도 통신회선의 신뢰성 제고, 실시간 처리에는 부적합한 에러 제어 방법 : 오류 검출, 수신 여부 피드백, 재전송 기능 등이 필요
■ Stop and Wait : 한 번에 하나씩 긍정 확인응답(ACK)을 받고, 후속 데이터 전송 : 가장 단순하나, 다소 비효율적 : 반이중 방식에서도 가능(Pipelining를 이용하여 효율 증가)
■ Go back N(GBN or Continuous ARQ) : Pipelining Protocol : 반이중 방식 : Sliding Window 방식 : 한번에 여러 개를 보낸후 하나의 긍정 확인응답(ACK)을 받고, 후속 데이터 전송. : 발신자는 패킷 n에 대해 timeout 발생시 패킷 n과 window 안에 있는 seq #이 n보다 높은 모든 패킷을 재전송 : 수신자가 예기치 않은 패킷을 받을 경우, 그 패킷을 버리고 가장 최근에 받은 패킷의 ACK를 재전송
■ Selective Repeat : Pipelining Protocol : 전이중 방식 : Go back N 과 비슷하지만 오류가 발생된 패킷 이후 또는 오류 발생된 패킷만을 재전송 : 수신자는 순서가 다르더라도 Receiver Window 안에 포함되는 패킷이라면 받을수 있으며 Buffer 해놓음.
- Client-Server - Peer-to-Peer (P2P) - Hybrid of client-server and p2p
Processes communicating : 같은 호스트간의 프로세스간 통신은 IPC(Inter-process communication) : 다른 호스트간의 통신은 Server process, Client process 로 이루어짐
- Sockets : 발신자/수신자에게 메세지를 송수신하는 프로세스 : 일종의 "door" 역할
- Addressing processes : 수신 메세지를 받기위해 프로세스는 반드시 identifier를 가져야한다. : host는 유일한 32-bit(IPv4) IP address를 가진다. : identifier = IP address + PORT numbers
Application protocol defines : Types of messages exchanged (request, response) : syntax, semantics : 프로세스들이 언제, 어떻게 메세지를 주고 받는지에 대한 규칙
Web and HTTP : Web page 는 HTML file, JPEG image, Java applet, audio file 등의 객체들로 구성, HTML-file이 베이스 : 각 객체들은 자체 주소(URL)을 가지고 있음
- HTTP : HyperText Transfer Protocol : 웹 어플리케이션 레이어 프로토콜 : client/server model : client? 브라우저가 requests, receives 한 웹 객체를 디스플레이 함 : server? web server가 요청에 대한 응답으로 객체를 전송 : http는 stateless protocol -> 서버는 클라이언트의 과거 요청을 유지하지 않음 : RTT? RoundTripTime으로 클라이언트 요청이 서버로 응답이 오는 시간
■TCP 사용 1. 클라이언트는 TCP Connection을 초기화 함(소켓을 만듦),PORT 80 2. 서버는 클라이언트로부터 TCP Connection을 받음 3. 브라우저(HTTP clinet)와 웹서버(HTTP server)간 HTTP messages를 주고 받음 4. TCP Connection 종료
■ Nonpersistent HTTP : 하나의 객체만 TCP를 통해 전송 : HTTP 1.0에서 사용 : Response time? total = 2RTT + transmit time : 객체(파일, 이미지 등)마다 2RTT와 TCP 연결에 대한 오버헤드 발생
■ Persistent HTTP : 다수의 객체를 TCP를 통해 전송 : HTTP 1.1에서 default로 사용 : 서버는 응답을 보낸 후에도 Connection을 열어둠 : client는 참조 객체를 마주했을 때 요청을 보냄 : 객체마다 1RTT의 오버헤드가 감소함
ex) If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT
×
○
Max-Forwards
이 메시지가 거쳐 갈수 있는 최대 Proxy의 개수를 지정
ex)Max-Forwards: 7
×
○
Proxy-Authorization
비공개 프록시 서버 유저인증을 위한 코드
×
○
Range
자원의 일부분만 받을때(이어받기기능) 받을범위 지정
ex)bytes=0-499 : <- 0~499byte를 얻고자 할 때.
×
○
■ Method
■ GET vs. POST : GET? URL 필드를 이용하여 업로드 : POST? entity body를 이용하여 업로드 : GET은 해당 요청을 몇번을 수행해도 해당 요청에 대한 결과가 계속 동일하게 돌아오는 것을 의미하며, POST는 해당 요청이 수행되면 서버에서 무언가 바뀌고, 동일한 결과가 돌아오는 것을 보장할 수 없다는 것을 의미한다. : POST의 경우 GET과는 달리 쿼리스트링(query string)의 글자 수 제약이 없으며, 파일업로드 등의 동작이 가능하다. 그리고 POST의 경우 쿼리스트링이 URL에 포함되지 않기때문에 user에게 파라메터 값 등을 덜 노출한 상태로 요청이 가능하다. 하지만 결국 HTTP 요청은 SSL을 이용하는 https가 아닌경우 plain text로 이루어게되고, 그러다보니 요청을 열어보면 쿼리스트링이 동일하게 보이는것은 마찬가지라 특별히 보안상 더 뛰어나다고는 말하기 힘들다.
GET 요청은 브라우저에서 캐시를 할 수 있다.
글을 작성하는 요청인데 GET 방식으로 글내용과 제목을 받아서 서버로 전송한다면, 해당 GET 요청과 그에 대한 응답이 브라우저에 의해 캐쉬가 되었다가 다시 사용될 우려가 있다. 이 경우 캐쉬에의해 자동으로 동일한 글을 또 작성하는 동작이 서버에서 발생될 수 있는데 이것은 심각한 오류이다.
검색봇(크롤러)으로 인한 문제 발생
구글이나 네이버의 검색봇(bot 혹은 crawler)들이 웹페이지 수집을 위해 해당 웹서버에 GET 요청을 할 수 있다. 이때 이러한 봇의 요청에 의해 게시판에 엉뚱한 데이터로 글이 작성되어 올라간다던지, 서버쪽의 데이터가 바뀐다면 당황스러운 일들이 발생할 가능성이 크다.
ex)Retry-After: Fri, 31 Dec 1999 23:59:59 GMT(Time)
Retry-After: 120 (Second)
×
○
Warning
상태코드와 응답 구문에 추가적인 경고
×
○
Vary
×
○
■ Status codes (출처 : http://coffeenix.net/doc/network/http_1_0_vs_1_1.html)
1xx: Informational -
요구메시지를 받은 후
연결 중 작업할 때.
2xx: Success -
요구메시지를 제대로 받았을 때.
3xx: Redirection -
요구메시지를 수행하기 위해
다른 작업이 필요할 때.
4xx: Client Error -
요구 메시지의 형식이 틀리거나
빠진 부분이 있을 때.
5xx: Server Error -
서버에 문제가 있을 때.
100 Continue
200 OK
성공처리
300 Multiple Choices
(실제 발생하지 않음)
400 Bad Request
요구가 올바르지 않음
500 Internal Server Error
예기치 못한 서버처리오류
101 Switching Protocols
201 Created
요구에따라 새로운자원생성(PUT)
301 Moved Permanently
URL이 확정적으로 옮겨짐
401 Unauthorized
사용자 인증이 필요
501 Not Implemented
요구에 대한 지원불가
(transfer-Encoding)
202 Accepted
요구를 이해하였으며 진행중
302 Moved Temporarily
URL이 임시적으로 옮겨짐
402 Payment Require
502 Bad Gateway
게이트웨이·프락시의 응답오류
203 Non-Authoritative Information
303 See Other
403 Forbidden
요구는 이해하나 수행거절(PUT)
503 Service Unavailable
서버부하로 응답불가
204 No Content
요구자료에 정보가 없음(empty)
304 Not Modified(If-Modified-Since)
수정날짜에 수정되지 않음
404 Not Found
요구한 파일이 없음
504 Gateway Time-out
205 Reser Content
305 Use Proxy
405 Method Not Allowed
허락된 메소드가 아님
505 HTTP Version not supported
(요구를 무시할 수 있음..??)
206 Partial Content
406 Not Acceptable
407 Proxy Authentication Required
408 Request Time-out
409 Conflict
410 Gone
411 Length Required
412 Precondition Failed
413 Request Entity Too Large
414 Request-URI Too Large
415 Unsupported Media Type
- Cookies : server는 response를 보내고 나면 그 client는 잊어버린다. 웹사이트가 user를 구별하기 원하거나, user access를 제한하기를 원한다면? : cookies에는 그 user를 위한 identifier가 담겨있다. 1. set-cookie header 를 HTTP response message에 포함 2. cookie header는 request message에 포함 3. cookie 파일은 user의 host에 계속 있고, user의 브라우저에 의해 관리된다. 4. Back-end Database는 웹 사이트에 있다. : 세션유지에 사용
Persistent Cookie: 브라우저를 종료해도 사용자의 하드드라이브에 저장. 만료시기가 되면 삭제 Session Cookie: 웹 클라이언트(IE) CASH에 임시 저장. 삭제 시기는 서버에서 만료되면 삭제
- Session : 사전적 의미로 "시간"을 의미 : 클라이언트와 웹 서버간에 통신 연결에서 두 개체의 활성화된 접속을 뜻함 : 클라이언트가 웹서버에 요청하여 처음 접속하면 JSP나 ASP 엔진은 요청한 클라이언트에 대하여 유일한 ID를 부여하게 되는데 이 ID를 세션이라 부름 : 세션 ID를 임시로 저장하여 페이지 이동 시 이용하거나, 클라리언트가 재접속 했을 때 클라이언트를 구분할 수 있는 유일한 수단 : 각각의 클라이언트마다 고유의 ID부여, Session 객체들마다 저장해 둔 Data를 이용, 클라이언트 자신만의 고유한 페이지를 열어놓아서 생길 수 있는 보안상의 문제 해결 능력
- Session vs. Cookie : Session은 서버 쪽에 정보를 저장하고, 쿠키는 클라이언트 쪽에 정보를 저장한다는 것이 가장 큰 차이점
- Web caches(proxy server) : 클라이언트 요청에 대한 응답시간을 줄이고, 트래픽을 줄이기 위해 사용 : cache 되지 않은 객체에 있어서는 낮은 성능, 또 cache 되어 있는 객체가 최신의 것이 아닐 수 도 있다. (해결 방안으로 If-Modified-Since)
FTP : File Transfer Protocol, RFC 959 : 다른 host로부터 혹은 다른 host로 file을 전송할 때 사용하는 프로토콜 : stateful protocol : client - server model : transport protocol로 TCP 사용, FTP server는 PORT 21로 control connection(out-of-band), client는 PORT 20로 data connection : 암호화가 필요하여 최근에는 SFTP나 FTPS로 대체
Electronic Mail : 주요 3가지 컴포넌트로 user agents, mail servers, SMTP(Simple Mail Transfer Protocol)로 구성 : user agents? mail reader, mail을 읽고, 편집 : mail servers? mailbox + message queue + SMTP
: SMTP? mail server 사이에서 메시지 전달을 위해 적용되는 프로토콜 :transport protocol로 TCP 사용, PORT 25 : persistent connection(여러 메시지를 하나의 TCP connection에서 전송 가능) : handshaking(greeting) -> transfer of message -> closure
- HTTP vs. SMTP : HTTP 1.1과 SMTP 둘다 persistent connection : 둘다 ASCII 커맨드, status code를 가짐 : HTTP는 pull로 client가 요청으로 정보를 끌어옴, SMTP는 push로 요청하지 않아도 server가 mailbox까지 정보를 줌. : HTTP는 각 개체가 캡슐화, SMTP는 한 msg안에 여러 객체가 담긴다.
- Mail access protocols : POP? Post Office Protocol, TCP 사용, download-and-keep, stateless across sessions : IMAP4? Internet Mail Access Protocol, 메세지 ID와 폴더 이름 간 매핑하여 user에게 접근 허가, user stateful across sessions : HTTP? gmail, naver 등
DNS : Domain Name System : IP 주소와 Name의 mapping가 필요함 -> name-address resolution : hostname을 ip주소로 변환, host aliasing, mail server aliasing, load distribution : UDP/TCP 둘 다 사용가능하지만 주로 UDP 사용, PORT 53 : 트래픽, single point of failure, 거리, 확장성 등의 문제로 중앙 집권 구조로 구현하지 않고, 분산 데이터베이스로 많은 name server의 계층형태로 구현
: www.amazon.com의 ip 주소를 얻는 과정 1. client가 root server로 com DNS server를 찾기위해 query를 보낸다. 2. client가 com DNS server로 amazon.com DNS server를 찾기위해 query를 보낸다. 3. client가 amazon.com DNS server로 www.amazon.com의 ip 주소를 얻기 위해 query를 보낸다. -> 주소의 역순으로 접근하면서 ip주소를 찾아감 : Root DNS server : 13개 (A~M) 세계적으로 존재 : Top-level domain (TLD) servers? com, org, net, edu, etc, kr, uk, fr, ca, jp 등 : Authoritative DNS servers? 어떤 단체에 대한 DNS 실제적인 IP주소 : Local Name Server? 엄격한 계층구조가 아닌 각 ISP(default name server)를 하나씩 가지고 있음, host가 DNS query를 생성하면 query가 DNS server로 전송, 마치 프록시처럼 계층적으로 query 전달 : caching and updating records
- DNS name resolution
:iterated query:recursive query
P2P
- BitTorrent : File은 256KB chunks로 쪼개짐 : peer joining torrent: 시간이 흐름에 따라 chunk가 쌓인다. tracker로 등록하여 주번 peer list를 얻음 : 다운로드 하는 동안 peer는 chunk를 다른 chunk부터 요청하여 받음, 가장 귀한 chunk부터 요청하여 받음) : Free Riding 방지 -> Tit-for-tat -> 많이 주는 쪽을 top-four providers로 선정
- Centralized index : peer들의 정보(ip, content)를 중앙서버에서 찾는 구조 : single point of failure, 병목현상등의 문제 발생
- DHT : Distributed Hash Table = Distributed P2P database : DB는 (id, value) pairs 를 가짐, 각 peer 들은 query를 이용하여 (key, value) peers을 얻어낼 수 있음 : Shortcuts(peer를 찾는 가장 짧은 경로), Peer Churn(Peer가 떠날 경우 successor를 새로 지정)
인터넷이란? : "nuts and bolts" : QoS(Quality of Service)는 다른 응용 프로그램, 사용자, 데이터 흐름 등에 우선 순위를 정하여, 데이터 전송에 특정 수준의 성능을 보장하기 위한 능력
- 네트워크 구성요소 : hosts, communication links, routers
- QOS : 최선 노력 서비스 (Best-Effort Service) : 현행 인터넷은 Dummy network이라하여 망측은 단순 멍청하고 단말측이 지능적인 역할을 하는 구조 따라서, 망측에서는 IP가 데이타그램의 전송을 위하여 최대의 노력을 하지만, 확실한 전송의 보장을 하지는 않음. 즉, 데이타의 흐름이 많거나 적거나 간에 시간지연이 없도록 하는 등의 신뢰성을 보증하지 않음 : 이와 같이 양단간 사용자에게 네트워크측에서 보장은 못하지만 최선의 서비스 제공을 하려는 서비스 모델을 최선 노력 서비스 (Best-Effort Service) 모델이라고 함
- 프로토콜 :통신 프로토콜또는통신 규약은컴퓨터나원거리 통신장비 사이에서 메시지를 주고 받는 양식과 규칙의 체계이다. 통신 프로토콜은 신호 체계,인증, 그리고 오류 감지 및 수정 기능을 포함할 수 있다. 프로토콜은 형식, 의미론, 그리고 통신의 동기 과정 등을 정의하기는 하지만 구현되는 방법과는 독립적이다. 따라서 프로토콜은 하드웨어 또는 소프트웨어 그리고 때로는 모두를 사용하여 구현되기도 한다.
Network edge : end systems, access networks, links
- Access networks : Modem, DSL(Digital Subscriber Line), HFC(Hybrid Fiber Coax, 동축케이블), FTTH(Fiber To The Home) : Modem은 같은 주파수 대역을 사용하기 때문에 전화와 인터넷 동시 사용 불가 : DSL은 주파수의 높낮이에 따라 필터링하여 전화와 인터넷 동시 사용 가능 : HFC는 30Mbps downstream, 2Mbps upstream로 라우터에 대역 공유 : FTTH는 병목현상을 줄임
- Circuit switching : 공중교환전화망(public switched telephone network)에 사용 : 네트워크 리소스(대역폭 등)를 "pieces"로 나누어 연결마다 할당 : 유저가 적을 경우 고정된 대역폭으로 안정적임 : 데이터가 전송 중이지 않을 때도 대역폭 할당, 많은 유저가 사용시 생기는 딜레이 등의 단점
- Packet switching : 인터넷에 사용 : 데이터 스트림을 패킷 단위로으로 나눔 : Store-and-Forward 방식으로 라우터는 전송전에 완전한 패킷을 받음, Resource Sharing이 이루어짐, 각 패킷을 full link 대역폭 사용 : 리소스가 필요할 때만 할당 : 혼잡으로 인한 패킷 딜레이와 손실이 발생할 수 있으므로 신뢰성있는 프로토콜이 필요함
■ 패킷 딜레이의 4가지 요소
1. processing : bit 에러 체크 : 출력 링크 결정 2. queueing : 출력 링크에 전송을 위한 대기 시간 : 라우터의 혼잡 규모에 의존 3. tranmission delay : L / R : L = packet length(bits) : R = link bandwidth(bps)
4. propagation delay : d / s : d = length of physical link : s = propagation speed in medium (~2x10^8 m/sec)
■ 패킷 손실 : 큐가 가득 차있는 경우 해당 패킷이 이전 노드에 의해 재전송 되거나 버려진다.
■ 처리량 : 수신자, 발신자의 bits/ time unit 따라 달라짐
- Network structure : ISP? Internet Service Provider
Protocal Layers : 네트워크들은 매우 복잡함 : 각 계층별로 서비스를 구현한다면? : 복잡한 시스템을 모듈화하여 유지 보수 및 변화에 용이
- Protocol Interfaces
: 각 프로토콜은 2가지 인터페이스가 있다.
1. service interface: operations on this protocol
2. peer-to-peer interface: messages exchanged with peer
: Layer n is the "service provider" for Layer n+1
: n-PDU = Header(PCI) + n-SDU
: n-PDU = (n-1)-SDU
SDU: Service Data Unit
SAP: Service Access Point
PCI: Protocol Control Information
PDU: Protocol Data Unit
- Encapsulation & De
capsulation
네트워크 보안 - Trojan horse : 유용한 소프트웨어에 숨어 있는 것
- Virus : e-mail 등으로 능동적으로 실행 :자가증식하면서 다른 호스트들도 감염시킴 - Worm : 수동적으로 실행하게 함 :자가증식하면서 다른 호스트들도 감염시킴
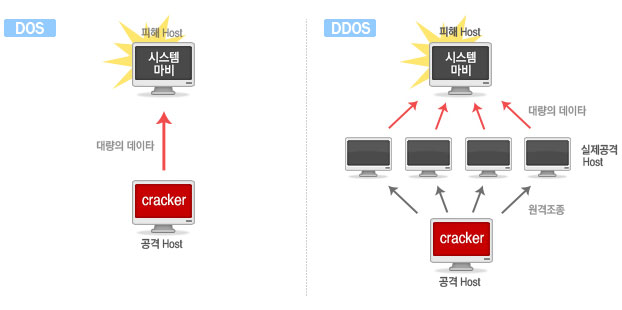
- DoS(Denial of Service), DDoS(Distributed Denial of Service) - Packet sniffing
[a] InnoDB support for geospatial indexing is available in MySQL 5.7.5 and higher.
[b] InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature.
[c] InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and higher.
[d] Compressed MyISAM tables are supported only when using the compressed row format. Tables using the compressed row format with MyISAM are read only.
[e] Compressed InnoDB tables require the InnoDB Barracuda file format.
[f] Implemented in the server (via encryption functions), rather than in the storage engine.
[g] Implemented in the server, rather than in the storage engine.
[h] Implemented in the server, rather than in the storage engine.
쿼리캐시(Query cache)는 타 DBMS에는 없는 MySql의 독특한 기능중 하나입니다.
여러가지 복잡한 처리와 꽤 큰 비용을 들여 실행된 결과를 쿼리 캐시에 담아두고, 동일한 쿼리 요청이 왔을때 간단하게 쿼리 캐시에서 찾아서 바로 결과를 내려줄수 있습니다. 즉, 빈번한 SELECT 쿼리의 성능 향상을 위해 사용합니다. 쿼리 캐시는 단어의 의미와는 달리 SQL문장을 캐시하는 것이 아니라 쿼리의 결과를 메모리에 캐시해두는 기능으로 아래와 같은 특징이 있습니다.
테이블에 변화(INSERT,UPDATE,DELETE)가 일어나게 되면 해당테이블과 관련된 쿼리 캐시내의 쿼리는 초기화
Query_cache_size 환경 변수를 통해서 조절(기본은 비활성화)
SHOW STATUS LIKE 'Qcache_%' 커맨드로 쿼리 캐시 관련 항목 모니터링
RESET QUERY CACHE 커맨드를 통해 수동으로 캐시 삭제 가능
그 밖에 Query_cache_limit(저장 쿼리 사이즈제한) 나 Query_cache_min_res_unit(쿼리 개시 조각화 사이즈) 등과 같은 옵션을 통해 성능 조절이 가능합니다.
아래는 쿼리 캐시를 내려주기 전 확인 과정입니다.
요청된 쿼리문장이 쿼리 캐시에 존재하는가?
해당사용자가 그 결과를 볼수 있는 권한을 가지고 있는가?
트랜젝션 내에서 실행된 쿼리인경우 가시범위 내의 트랜잭션에서 만들어진 결과인가?
쿼리에 사용된 기능(내장 함수나 저장함수등)이 캐시돼도 동일한 결과를 보장할 수 있는가?
CURRENT_DATE(), SYSDATE(), RAND()등과 같이 호출시점에 따라 결과가 달라지는 요소가 있는가?
원자성(Atomicity) - 트래잭션과 관련된 작업들이 모두 수행되었는지 아니면 모두 실행이 안되었는지를 보장하는 능력이다. 자금 이체는 성공할 수도 실패할 수도 있지만 원자성은 중간 단계까지 실행되고 실패하는 일은 없도록 하는 것이다.
일관성(Consistency) - 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
격리성(Isolation) - 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다. 이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다. 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다.
지속성(Durability) - 성공적으로 수행된 트랜잭션은 영원히 반영되야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되야 함을 의미한다. 전형적으로 모드 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
일관성과 격리성은 쉽게 정의하기 힘들지만, 이 두 가지 속성은 서로 다른 두 개의 트랜잭션에서 동일 데이터를 조회하고 변경하는 경우에도 상호 간섭이 없어야 한다는 것을 의미한다.
InnoDB의 모든 테이블은 기본적으로 Primary Key를 기준으로 클러스터링되어 저장된다. 즉,Primary Key 값의 순서대로 디스크에 저장된다는 뜻이며, 이로 인해 Primary Key에 의한 Range Scan은 상당히 빨리 처리될수 있다. (오라클 DBMS의 IOT(Index Organized Table)와 동일한 구조)
일반적으로 어플리케이션에서는 INSERT나 UPDATE 그리고 DELETE와 같이 데이터를 변경하는 쿼리는 데이터 파일의 이곳저고에 위치한 레코드를 변경하기 때문에 Random I/O 를 발생시킨다. 하지만 버퍼풀이 이러한 변경된 데이터를 모아서 처리하게 되면 Random I/O 작업의 횟수를 줄일수 있다.
MyISAM 키 캐시가 인덱스의 캐시만을 처리하는데 비해, InnoDB의 버퍼 풀은 데이터와 인덱스 모두 캐시 하고 쓰기 버퍼링의 역할 까지 모두 처리한다. 그밖에도 InnoDB의 버퍼 풀은 많은 백그라운드 작업의 기반이 되는 메모리 공간이다. 따라서 버퍼 풀의 크기를 설정하는 파라미터 (innodb_buffer_pool_size) 는 신중하게 설정해야 한다. 일반적으로 전체 장착된 물리 메모리의 50~80% 수준에서 버버풀의 메모리 크기를 결정한다.
언두 영역은 UPDATE문장이나 DELETE와 같은 문장으로 데이터를 변경했을 때 변경되지 전의 데이터(이전 데이터)를 보관하는 곳이다. 특정한 데이터를 변경하였다면 사용자가 커밋시에 현재 상태가 그대로 유지되고 롤백하게 되면 언두 영역의 백업데이터를 다시 데이터 파일로 복구하게 된다. 언두의 데이터는 크게 두가지 용도로 사용되는데, 첫번째 용도가 트랜젝션의 롤백 대비용이다. 두번째 용도는 트랜젝션의 격리 수준을 유지 하면서 높은 동시성을 제공하는데 사용된다.
레코드가 INSERT되거나 UPDATE될때 데이터 파일을 변경하는 작업뿐 아니라 인덱스를 업데이트 하는 작업도 필요하다. 그런데 인덱스를 업데이트 하는 작업은 랜덤 하게 디스크를 읽는 작업을 필요로 하므로 테이블에 인덱스가 많다면 이 작업은 상당히 많은 자원을 소모 하게 된다. 그래서 InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만, 디스크로 부터 읽어 와야 한다면 임시공간에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상 시키는데, 이때 사용 하는 임시 메모리 공간을 인서트 버퍼(Insert Buffer)라고 한다.
데이터를 변경하고 커밋하면 DBMS는 데이터의 ACID를 보장하기 위해 즉시 변경된 내용을 데이터 파일로 기록해야 한다. 하지만 이러한 데이터 파일 변경작업은 랜덤 하게 디스크에 기록해야 하기 때문에 상당한 자원이 소모된다. 그래서 이러한 부하를 줄이기 위해 대부분의 DBMS에는 변경된 데이터를 버퍼링 해두기 위해 InnoDb 버퍼 풀 과 같은 장치가 포함되어 있다. 하지만 이장치 만으로는 ACID를 보장 할수 없는데 이를 위해 변경된 내용을 순차적으로 디스크에 기록하는 로그 파일을 가지고 있다. 일반적으로 DBMS에서 로그라 하면 이 리두 로그를 지칭하는 경우가 많다.
MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는데 있다. 멀티 버전이라는 것은 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다는 의미이다. 만약 격리수준이 READ_UNCOMMITED 인 경우 에는 InnoDb 버퍼 풀 이나 데이터 파일로 부터 변경되지 않은 데이터를 읽어서 반환한다. 즉, 데이터가 커밋됐든 아니든 변경된 상태의 데이터를 반환한다. 그렇지 않고 READ_COMMITTED나 그 이상의 격리 수준인 경우에는 아직 커밋되지 않았기 때문에 InnoDB의 버퍼 풀이나 데이터 파일에 있는 내용 대신 변경되기 전의 내용을 보관하고 있는 언두 영역 의 데이터를 반환한다. 이러한 과정을 MVCC라고 표현한다.
트랜젝션이 길어지면 언두에서 관리하는 예전 데이터가 삭제되지 못하고 오랫동안 관리 되어야 하며, 자연히 언두 영역이 저장되는 시스템 테이블 스페이스의 공간이 많이 늘어나야 하는 상황이 발생할수도 있다. 커밋이 된다고 언두 영역의 백업 데이터가 항상 바로 삭제되는것은 아니다. 언두 영역을 필요로 하는 트랜젝션이 더이상 없을때 비로소 삭제된다.
InnoDb에서 격리수준이 SERIALIZABLE이 아닌 경우 순수한 SELECT작업은 다름 트랜젝션의 변경 작업과 관계없이 항상 잠금을 대기 하지 않고 바로 실행 된다. 특정 사용자가 레코드를 변경하고 커밋을 수행하지 않았다 하더라도 이 변경 트랜젝션이 다른 사용자의 SELECT 작업을 방해 하지 않는다. 이를 잠금없는 일관된 읽기 라고 포현하며, 변경되기 전의 데이터를 읽기위해 언두(UnDo)로그를 사용한다. 오랜시간 동안 활성상태인 트랜젝션에 위해 MySql서버가 느려지거나 문제가 발생할때가 잇는데, 바로 이러한 일관된 읽기를 위해 언두 로그를 삭제하지 못하고 계속 유지 하기 때문에 발생하는 문제다. 트랜젝션이 시작 됐다면 가능한 빨리 롤백이나 커밋을 통해 트랜젝션을 완료 하는것이 좋다.
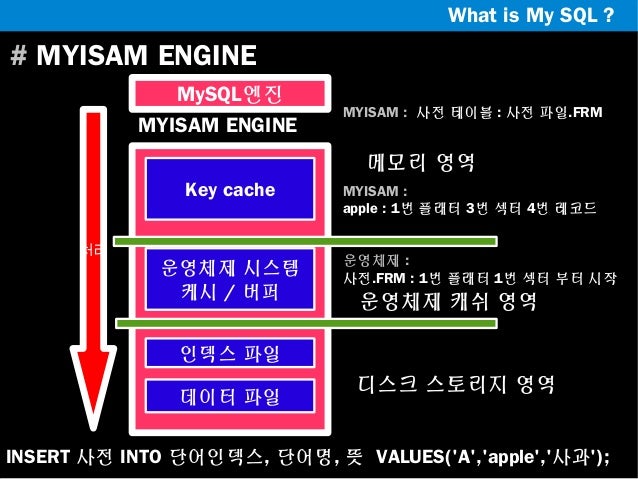
InnoDB의 버퍼풀의 비슷한 역활을 하는 것으로 MyISAM의 키캐시(Key cahe, 키버퍼)가 있다. MyISAM 테이블의 인덱스는 키캐시를 이용해 디스크를 검색하지 않고 검색할 수 있으나 MyISAM 테이블의 데이터는 디스크로부터의 I/O를 해결해 줄만한 어떠한 캐시나 버퍼링 기능이 존재하지 않는다. 따라서 MyISAM 테이블의 데이터 읽기나 쓰기 작업은 항상 운영체제의 디스크로부터 읽고 쓰는 파일에 대한 캐시나 버퍼링 메커니즘을 가지고 있다. 운영체제가 사용할 메모리가 어느정도 보장이 되어야 가능함 MyISAM의 주로 사용되는 키캐시는 물리 메모리의 40% 이상을 넘지 않게 설정하는것이 좋다고한다.
NDB는 Network Database 의 줄미말로 네트워크를 통해 데이터 분산을 지원하는 스토리지 엔진입니다. 부하분산을 하기 위한 방법중 Replication보다는 비교적 최근에 나온 기능입니다. NDB Cluster Storage Engine은 MySQL과는 별도의 프로세스로 동작해 클러스터링을 처리합니다. 결과적으로는 데이터 저장부분만 HA 형태로 운영이 가능한 아키텍처입니다.
MySQL 서버의 바이너리 로그만 클러스터간의 복제를 할수 없고 NDB 클러스터에는 2개 이상의 MySQL 서버가 동시에 쓰기와 읽기용 쿼리를 처리하게된다.
2개 이상의 MySQL 서버로부터 발생한 바이너리 로그를 동시에 발생시점순으로 하나의 슬레이브 MY-SQL 서버로 보낼수 없기 때문에 NDB 클러스터의 데이터 노드는 자기 자신에게 발생한 변경 내용을 SQL 노드로 피드백을 주며 자신의 바이너리 로그를 수정하고 이때 NDB Binlog injector 라는 스레드가 활성화 되는데 이 스레드가 바이너리 로그에 병합하는 역할을 담당한다.
트랜잭션 : 프로젝트 설계자 입장에서 보면 데이터베이스 내에서 하나의 그룹으로 처리해야 하는 명령문들을 모아놓은 작업 단위
트랜잭션 특징
- ACID ■ Atomicity (원자성) : 트랜잭션의 수행은 원자적이다.(All-OR-Nothing 방식) : 트랜잭션의 모든 연산들은 데이터베이스에 정상적으로 수행이 완전히 완료되거나 아니면, 어떠한 연산도 수행되지 않아야한다.
■ Consistency (일관성) : 트랜잭션 실행을 성공적으로 완료하면, 언제나 일관성 있는 데이터베이스 상태로 유지되어야 한다.
■ Isolation (격리성/고립성) : 트랜잭션들이 서로 독립성을 보장받으며 수행될 수 있도록 도와준다. : 다수의 트랜잭션이 동시에 병행 수행되고 있는 경우, 수행 중인 트랜잭션이 완전히 완료될 때까지 다른 트랜잭션에서 현재 수행 중인 트랜잭션의 중간 수행 결과를 참조 할 수 없도록 막아주는 것이다.
■ Durability (영속성/지속성) : 트랜잭션이 모든 작업을 성공적으로 수행 완료하여 데이터베이스 내에 반영했다면, 트랜잭션의 결과는 영구적이어야 한다.