출처: http://sejoong.github.io/dev/2015/02/15/dev/, HTTP 2.0 : The New Web Standard and Issue(허태성, saturn.twinfish@gmail.com)
HTTP 1.1 이후로 처음 등장한 새로운 버전인 HTTP/2.0을 알아보기 전에 HTTP가 무엇인지 알아보고 HTTP/2.0에서는 어떤 변화가 있는지 알아보자.
HTTP
HyperText Transfer Protocol의 약자로 WWW(World Wide Web)에서 하이퍼텍스트(hypertext) 문서를 교환하기 위하여 사용되는 통신규약이다.
1.0(1996s)m 1.1(1999s)두가지 버전이 있다.
- Status code:
http 통신중 요청의 상태 정보를 제공한다. 공식 적인 상태코드 목록은 IANA에서 확인할 수 있다.
상태코드의 첫 숫자는 응답의 종류를 나타낸다. 아래는 응답의 종류와 내가 개발중 많이 접했던 몇가지 상태 코드 이다.
- 1xx - Informational - 정보교환
- 2xx - Success - 성공
200 - OK - 요청이 성공적으로 전송됨 - 3xx - Redirection - 방향 지정
301 - Moved Permanently - 요청 페이지의 영구적인 위치 변화
302 - Found - 요청 페이지이 일시적인 위치 변화 - 4xx - Client Error - 클라이언트 오류
404 - Not Found - 요청받은 자원을 서버에서 찾을 수 없을때 나타나는 상태
405 - Method Not Allowed - 서버에서 사용자가 요청한 주소의 메소드를 지원하지 않을때 나타남 - 5xx - server Error - 서버 오류
Request methods:
요청이 수행될 작업의 방법을 나타낸다.- OPTIONS: 요청한 URL에 어떠한 메소드 요청이 가능한지 묻는다.
- GET: 다른 작업없이 데이터의 검색에 이용.
- HEAD: 데이터의 검색에 이용하나 GET과는 다르게 응답 HEADER만 받는다.
- POST: URL에 새로운 데이터를 보낼때 사용.
- PUT: URL에 저장될 정보를 보낸다.
- DELETE: URL의 리소스를 삭제한다.
- TRACE: 보낸 메세지를 다시 돌려받는다.
- CONNECT: 프록시에서 사용되는 예약 메소드.
- OPTIONS: 요청한 URL에 어떠한 메소드 요청이 가능한지 묻는다.
- 요청/응답 스펙
Request-Line
*(( general-header | request-header | entity-header ) CRLF)
CRLF
[ message-body ]
- Request-line: method, request url, http버전
- Request-header: general-header, request-header, entity-header가 존재하며 필요에 따라 사용
Status-Line
*(( general-header | response-header | entity-header ) CRLF)
CRLF
[ message-body ]
- status-line: http 버전, 상태 코드, 상태 메세지
- Request-header: general-header, response-header, entity-header
HTTP/2.0의 등장 배경 및 특징
latency를 줄여 웹의 속도를 개선하기 위해 등장.
1. HTTP Header 데이터 압축
2. Server Push(서버에서 부터 시작되는 전송)
3. HTTP 1에서 존재하던 head-of-line blocking 문제 개선
4. 싱글 TCP connection내에서 병렬 페이지 로딩 구현
2.0은 기존 버전인 1.1과의 높은 호환성(method, status codes 등)은 보장하고 클라이언트 서버 간 전송 및 프레임의 개선에 초점을 맞췄다.head-of-line blocking: 동일한 송신 포트 자원에 대한 처리량 경쟁으로 인해 처리량 지연 및 프레임 손실 발생 유발 작업대기 중인 2개의 패킷이 존재할 경우 첫번째 패킷이 대기중이면 그 뒤 패킷들은 무조건 대기할때 발생







HTTP 2.0의 개선 사항
- 효율적인 페이지 로딩을 위해 URL의 이미지, 스크립트등의 자원을 압축해 페이지 렌더링을 위한 요청횟수를 감소시켰다.
- 뿐만 아니라 server가 push가 가능해 웹페이지의 렌더링이 필요하단 사실을 알게되면 추가 요청없이 서버가 리소스를 제공한다.
- 그 외에도 성능 개선을 위한 요청 다중화, 헤더 압축, HOL Blocking해결을 위한 요청 우선순위 결정등이 있다.
HTTP/2.0과 SPDY와의 관계
SPDY:
Google이 ‘speedy’라는 단어를 기반으로 제안한 새로운 프로토콜이다. HTTP의 단점들을 보완하여, 인터넷 환경을 보다 효율적으로 이용하기 위한 프로토콜이다. HTTP/2.0에서는 스펙에 SPDY를 반영할 예정이다.특징:
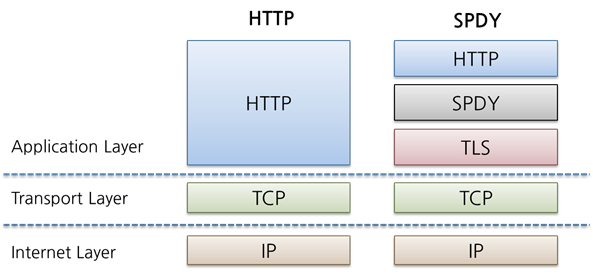
TLS 위에서 동작한다.
- https에서만 적용가능
HTTP 헤더를 압축한다.
- 요청마다 반복되는 내용을 압축해 성능 향상 효과가 나타남
바이너리로 프레임을 구성한다.
- 파싱 속도가 향상되고 오류확률은 낮아진다.
다중 연결을 지원한다.
- 다수의 요청, 응답 을 동시에 처리 할 수 있어 속도 향상
인터리빙을 허용한다.
- 우선순위가 높은 데이터가 더 빨리 전송 될 수있다.
- 서버 푸시가 가능하다.
결론
HTTP 1.1 이 사용하는 전송방식(RFC7230)에는 몇가지 문제점이 존재했다.
HTTP/1.0은 TCP connection에서 한번에 하나의 요청 만이 가능했고 HTTP/1.1에서는 그보다 발전하여 request pipelining을 사용했지만 여전히 HOL Blocking 문제가 존재했다.
HTTP/2.0은 오랫동안 변화하지 않았던 HTTP를 현 웹 환경에 맞게 발전시켜 속도의 향상을 도모 한다는데 크 의의가 있다.
참고: http://http2.github.io/http2-spec/#intro 참고: http://helloworld.naver.com/helloworld/140351
'Major > Network' 카테고리의 다른 글
| http vs https (0) | 2016.03.23 |
|---|---|
| 네트워크 - 총 정리 (0) | 2015.12.18 |
| 네트워크 - Link Layer (0) | 2015.12.17 |
| 네트워크 - Network Layer (0) | 2015.12.10 |
| 네트워크 - Transport Layer (0) | 2015.12.09 |