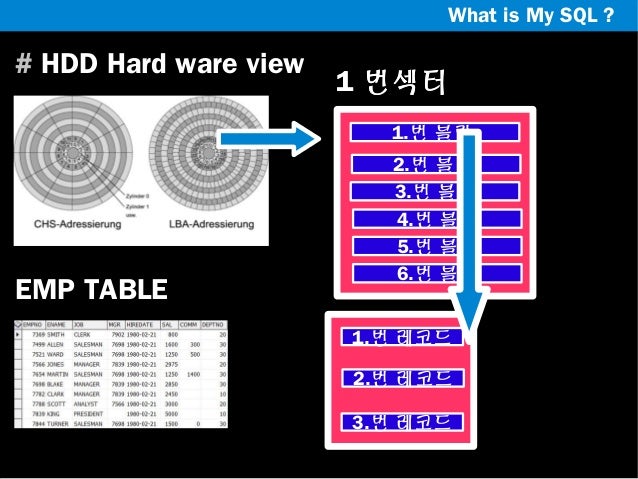
MySQL의 전체 구조
MySQL 은 다양한 접근 드라이버를 제공하여 거의 모든 언어를 이용해 쿼리를 사용할 수 있도록 지원합니다.
MySQL 서버는 크게 MySQL 엔진과 스토리지 엔진으로 구분해서 볼 수 있습니다. 그밖에 간단한 특징을 정리해보면 아래와 같습니다.
- Connection Pool 이 접속 제어
- SQL Support, Parser, Optimizer, Caches&Buffers 등의 앞단에서 쿼리를 처리
- MySQL은 Pluggable Storage Engines를 사용하여 InnoDB, MyISAM, Memory 같은 다양한 스토리지 엔진을 사용할수 있다
- 어플리케이션에 따라서 스토리지 엔진을 선택하여 사용할 수 있다.

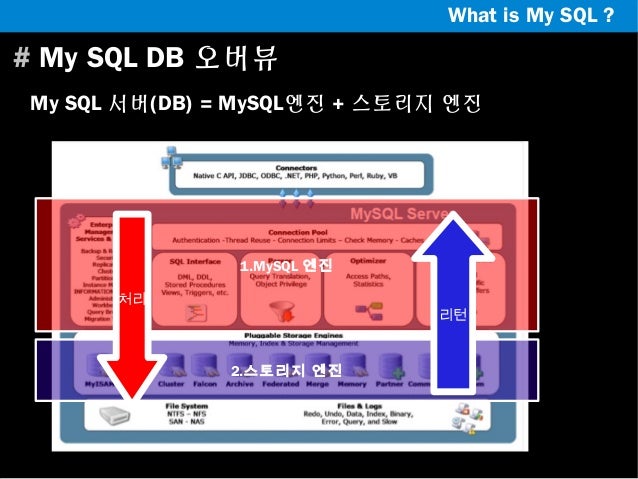
MySQL 엔진

- 클라이언트로 부터 접속 및 쿼리 요청을 처리하는 커넥션 핸들러와 SQL 파서 및 전처리기, 옵티마이저가 중심
- MyISAM의 키 캐시나 InnoDB의 버퍼 풀과 같은 보조 저장소 기능이 포함
- 요청된 SQL문장을 분석하거나 최적화
스토리지 엔진
- 데이터를 디스크 스토리지에 저장하거나 읽어오는 역할
- 여러개의 엔진을 동시에 사용할 수 있다.
- 테이블 생성 정의시 사용할 스토리지 엔진을 지정 할 수 있음 ( ENGINE = INNODB)
Table 14.1 Storage Engine Features
Feature MyISAM Memory InnoDB Archive NDB Storage limits 256TB RAM 64TB None 384EB Transactions No No Yes No Yes Locking granularity Table Table Row Row Row MVCC No No Yes No No Geospatial data type support Yes No Yes Yes Yes Geospatial indexing support Yes No Yes[a] No No B-tree indexes Yes Yes Yes No No T-tree indexes No No No No Yes Hash indexes No Yes No[b] No Yes Full-text search indexes Yes No Yes[c] No No Clustered indexes No No Yes No No Data caches No N/A Yes No Yes Index caches Yes N/A Yes No Yes Compressed data Yes[d] No Yes[e] Yes No Encrypted data[f] Yes Yes Yes Yes Yes Cluster database support No No No No Yes Replication support[g] Yes Yes Yes Yes Yes Foreign key support No No Yes No No Backup / point-in-time recovery[h] Yes Yes Yes Yes Yes Query cache support Yes Yes Yes Yes Yes Update statistics for data dictionary Yes Yes Yes Yes Yes [a] InnoDB support for geospatial indexing is available in MySQL 5.7.5 and higher.
[b] InnoDB utilizes hash indexes internally for its Adaptive Hash Index feature.
[c] InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and higher.
[d] Compressed MyISAM tables are supported only when using the compressed row format. Tables using the compressed row format with MyISAM are read only.
[e] Compressed InnoDB tables require the InnoDB Barracuda file format.
[f] Implemented in the server (via encryption functions), rather than in the storage engine.
[g] Implemented in the server, rather than in the storage engine.
[h] Implemented in the server, rather than in the storage engine.
핸들러 API
- 각 스토리지 엔진에 쓰기 또는 읽기를 요청하는 handler가 사용하는 API
- InnoDB 스토리지 엔진 또한 이 핸들러 API를 이용해 MySQL 엔진과 데이터를 주고 받는다.
- SHOW GLOBAL STATUS LIKE 'Handler%' 명령어로 핸들러 API를 통해 얼마나 많은 데이터 작업이 있었는지 확인할 수 있다.
MySQL 스레딩 구조
MySQL 서버는 프로세스 기반이 아닌 스레드 기반으로 동작하며 포그라운드 스레드와 백 그라운드 스레드로 구분됩니다.
포 그라운드 스레드 (클라이언트 스레드)
- MySQL 서버에 접속된 클라이언트 수만큼 존재함
- 각 클라이언트 사용자가 요청하는 쿼리 문장을 처리하는 것이 주 임무
- 데이터를 MySQL의 데이터 버터나 캐시로 부터 가져오며, 버퍼나 캐시가 없는 경우에는 직접 디스크의 데이터나 인덱스 파일로 부터 데이터를 읽어와서 작업을 처리한다.
- 스레드의 개수를 일정하게 유지하게 만들어 주는 파라미터: thread_cache_size
- InnoDB 테이블은 데이터 버퍼나 캐시까지만 포그라운드 스레드가 처리
- MyISAM 테이블은 디스크 쓰기까지 처리
백그라운드 스레드
- InnoDB 일 경우 백그라운드 스레드 처리가 많은 비중을 차지
- 인서트 버퍼 병합, 로그 기록, InnoDB 버퍼 풀의 데이터를 디스크에 기록등을 처리
- 로그 스레드와 버퍼의 데이터를 디스크로 내려쓰는 작업을 처리
메모리 할당 및 사용구조
MySql에서 사용되는 메모리 공간을 크게 글로벌 메모리 영역과 로컬 메모리 영역으로 구분할 수 있습니다.
글로벌 메모리 영역
- MySql서버가 시작되면서 운영체제로부터 할당 받는다.
- 클라이언트 스레드의 수와는 무관하게 하나의 메모리 공간만 할당 된다.
로컬 메모리 영역
- 세션 메모리 영역이라고도 표현하며, 클라이언트 스레드가 쿼리를 처리하는데 사용하는 메모리 영역이다.
- 클라이언트 스레드가 사용하는 메모리 공간이라고 해서 클라이언트 메모리 영역이라고도 한다.
쿼리 실행 구조
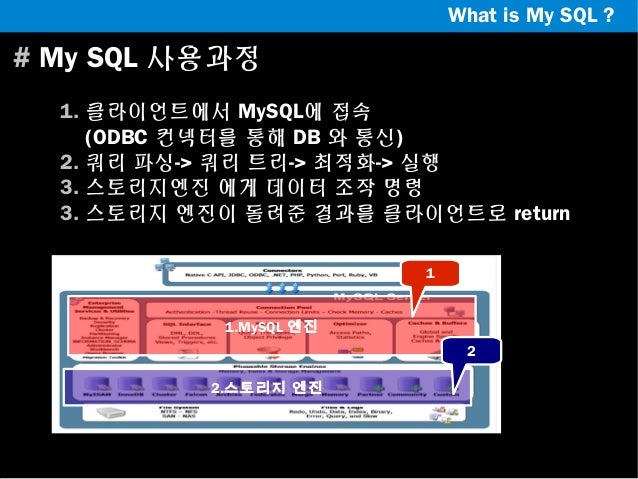
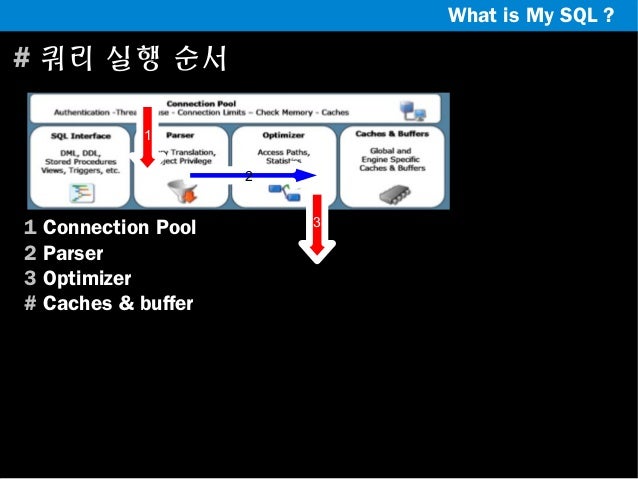
Client 에 의해 SQL 요청이 들어오면아래와 같은 순서로 쿼리가 실행됩니다.
파서
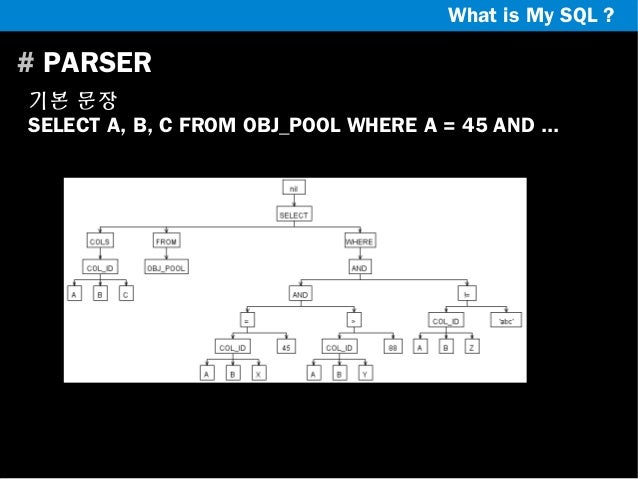
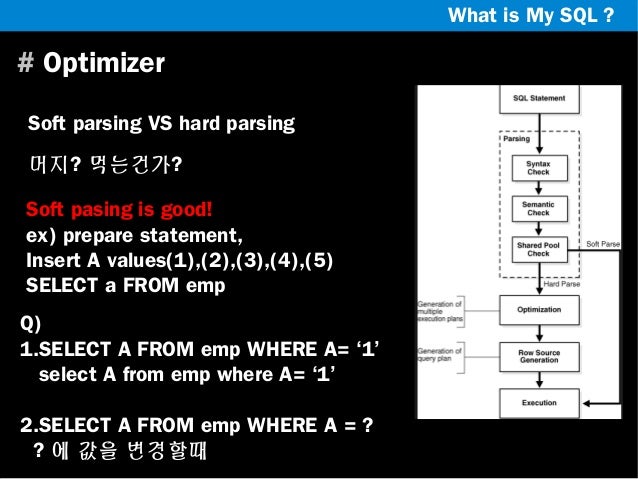
- 쿼리 문장을 토큰(MySQL이 인식할수 있는 최소단위의 어휘나 기호)으로 분리해 트리 형태의 구조로 만들어 내는 과정.
- 기본문법 오류를 발견하고 사용자에게 전달
전처리기
- 파서 트리를 기반으로 쿼리문장의 구조적인 문제점을 확인
- 각 토큰을 테이블 이름이나 컬럼명 또는 내장 함수와 같은 개체를 매핑해 해당 객체의 존재 여부와 객체의 접근권한등을 확인하는 과정
- 권한상 사용할 수 없는 개체의 토큰은 이 단계에서 걸러진다.
옵티마이저
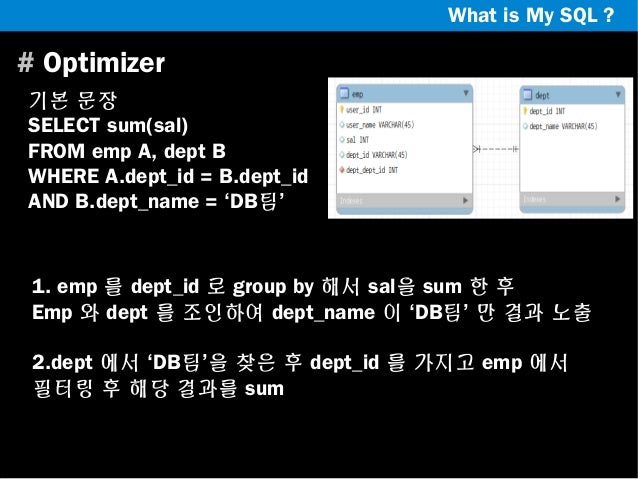
- 사용자가 요청한 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정
- 쿼리 변환
- 비용 최적화
- 실행계획 개선
이후 쿼리실행기는 스토리지 엔진에 따라 SQL 실행 결과를 사용자나 다른 연결요청 모듈에 넘기게 됩니다. 
쿼리 캐시
쿼리캐시(Query cache)는 타 DBMS에는 없는 MySql의 독특한 기능중 하나입니다.
여러가지 복잡한 처리와 꽤 큰 비용을 들여 실행된 결과를 쿼리 캐시에 담아두고, 동일한 쿼리 요청이 왔을때 간단하게 쿼리 캐시에서
찾아서 바로 결과를 내려줄수 있습니다. 즉, 빈번한 SELECT 쿼리의 성능 향상을 위해 사용합니다.
쿼리 캐시는 단어의 의미와는 달리 SQL문장을 캐시하는 것이 아니라 쿼리의 결과를 메모리에 캐시해두는 기능으로 아래와 같은 특징이 있습니다.
- 테이블에 변화(INSERT,UPDATE,DELETE)가 일어나게 되면 해당테이블과 관련된 쿼리 캐시내의 쿼리는 초기화
- Query_cache_size 환경 변수를 통해서 조절(기본은 비활성화)
- SHOW STATUS LIKE 'Qcache_%' 커맨드로 쿼리 캐시 관련 항목 모니터링
- RESET QUERY CACHE 커맨드를 통해 수동으로 캐시 삭제 가능
- 그 밖에 Query_cache_limit(저장 쿼리 사이즈제한) 나 Query_cache_min_res_unit(쿼리 개시 조각화 사이즈) 등과 같은 옵션을 통해 성능 조절이 가능합니다.
아래는 쿼리 캐시를 내려주기 전 확인 과정입니다.
- 요청된 쿼리문장이 쿼리 캐시에 존재하는가?
- 해당사용자가 그 결과를 볼수 있는 권한을 가지고 있는가?
- 트랜젝션 내에서 실행된 쿼리인경우 가시범위 내의 트랜잭션에서 만들어진 결과인가?
- 쿼리에 사용된 기능(내장 함수나 저장함수등)이 캐시돼도 동일한 결과를 보장할 수 있는가?
- CURRENT_DATE(), SYSDATE(), RAND()등과 같이 호출시점에 따라 결과가 달라지는 요소가 있는가?
- Prepared Statement 의 경우 변수가 결과에 영향을 미치지 않는가?
- 캐시가 만들어지고 난후 해당 데이터가 다른 사용자에 의해 변경되지 않았는가?
- 쿼리에 의해 만들어진 결과가 캐시하기에 너무 크지 않은가?
- 그 밖에 쿼리 캐시를 사용하지 못하게 만드는 요소가 사용되었는가?
InnoDB 스토리지 엔진
읽어볼만한 자료 : InnoDB vs MyISAM 비교
InnoDB 의 기본적인 특징은 아래와 같습니다.
- ACID 트랜잭션 지원
- 테이블스페이스당 64TB 저장 지원
- MyISAM보다 데이터 저장 비율이 낮음
- 다른 엔진들에 비해서 느린 데이터 로드 속도
- MVCC/Snapshot read 지원
- B-tree, clustered 인덱스 지원
- 데이터와 인덱스 메모리 캐시 지원
- 외부키 지원
- 데이터 압축 옵션을 제공하지 않음
- row레벨 락을 지원 하며 isolation 레벨 지원
- 자동 에러 복구 기능
- 백업 및 특정 시점으로 복구 지원
원자성(Atomicity)
- 트래잭션과 관련된 작업들이 모두 수행되었는지 아니면 모두 실행이 안되었는지를 보장하는 능력이다. 자금 이체는 성공할 수도 실패할 수도 있지만 원자성은 중간 단계까지 실행되고 실패하는 일은 없도록 하는 것이다.
일관성(Consistency)
- 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
격리성(Isolation)
- 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다. 이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다. 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다.
지속성(Durability)
- 성공적으로 수행된 트랜잭션은 영원히 반영되야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되야 함을 의미한다. 전형적으로 모드 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
일관성과 격리성은 쉽게 정의하기 힘들지만, 이 두 가지 속성은 서로 다른 두 개의 트랜잭션에서 동일 데이터를 조회하고 변경하는 경우에도 상호 간섭이 없어야 한다는 것을 의미한다.
InnoDB 구조와 특성

프라이머리 키에 의한 클러스터링
InnoDB의 모든 테이블은 기본적으로 Primary Key를 기준으로 클러스터링되어 저장된다. 즉,Primary Key 값의 순서대로 디스크에
저장된다는 뜻이며, 이로 인해 Primary Key에 의한 Range Scan은 상당히 빨리 처리될수 있다. (오라클 DBMS의 IOT(Index Organized Table)와 동일한 구조)
잠금이 필요없는 일관된 읽기
MVCC(Multi Version Concurrency Control)라는 기술을 이용해 락을 걸지 않고 읽기 작업을 수행한다.
자동 데드락 감지
InnoDb는 그래프 기반의 데드락 체크 방식을 사용하기 때문에 감지가 용이하고, 감지된 데드락은 관련 트랜젝션 증에서 ROLLBACL이 가장 용이한 트랜젝션, 즉 레코드를 가장 적게 변경한 트렌젝션을 자동적으로 강제 종료해 버린다.
자동화된 장애복구
MySql서버가 시작될때 완료되지 못한 트랜젝션이나 디스크에 일부만 기록된 데이터페이지 등에 대한 일련의 복구 작업이 자동으로 진행된다.
오라클의 아키텍처 적용
InnoDB스토리지 엔진은 오라클 DBMS의 기능과 유사한점이 많다. 대표적으로 MVCC기능이 제공된다는것과 언두(UnDo)데이터가 시스템 테이블 스페이스에 관리 된다는 것 등이다.
InnoDB 버퍼 풀
일반적으로 어플리케이션에서는 INSERT나 UPDATE 그리고 DELETE와 같이 데이터를 변경하는 쿼리는 데이터 파일의 이곳저고에 위치한 레코드를 변경하기 때문에 Random I/O 를 발생시킨다. 하지만 버퍼풀이 이러한 변경된 데이터를 모아서 처리하게 되면 Random I/O 작업의 횟수를 줄일수 있다.
MyISAM 키 캐시가 인덱스의 캐시만을 처리하는데 비해, InnoDB의 버퍼 풀은 데이터와 인덱스 모두 캐시 하고 쓰기 버퍼링의 역할 까지 모두 처리한다. 그밖에도 InnoDB의 버퍼 풀은 많은 백그라운드 작업의 기반이 되는 메모리 공간이다. 따라서 버퍼 풀의 크기를 설정하는 파라미터 (innodb_buffer_pool_size) 는 신중하게 설정해야 한다. 일반적으로 전체 장착된 물리 메모리의 50~80% 수준에서 버버풀의 메모리 크기를 결정한다.
언두(UnDo)로그
언두 영역은 UPDATE문장이나 DELETE와 같은 문장으로 데이터를 변경했을 때 변경되지 전의 데이터(이전 데이터)를 보관하는 곳이다. 특정한 데이터를 변경하였다면 사용자가 커밋시에 현재 상태가 그대로 유지되고 롤백하게 되면 언두 영역의 백업데이터를 다시 데이터 파일로 복구하게 된다.
언두의 데이터는 크게 두가지 용도로 사용되는데, 첫번째 용도가 트랜젝션의 롤백 대비용이다. 두번째 용도는 트랜젝션의 격리 수준을
유지 하면서 높은 동시성을 제공하는데 사용된다.
인서트 버퍼(insert buffer)
레코드가 INSERT되거나 UPDATE될때 데이터 파일을 변경하는 작업뿐 아니라 인덱스를 업데이트 하는 작업도 필요하다.
그런데 인덱스를 업데이트 하는 작업은 랜덤 하게 디스크를 읽는 작업을 필요로 하므로 테이블에 인덱스가 많다면 이 작업은 상당히
많은 자원을 소모 하게 된다.
그래서 InnoDB는 변경해야 할 인덱스 페이지가 버퍼 풀에 있으면 바로 업데이트를 수행하지만, 디스크로 부터 읽어 와야 한다면
임시공간에 저장해 두고 바로 사용자에게 결과를 반환하는 형태로 성능을 향상 시키는데, 이때 사용 하는 임시 메모리 공간을
인서트 버퍼(Insert Buffer)라고 한다.
리두(ReDo)로그 및 로그 버퍼
데이터를 변경하고 커밋하면 DBMS는 데이터의 ACID를 보장하기 위해 즉시 변경된 내용을 데이터 파일로 기록해야 한다.
하지만 이러한 데이터 파일 변경작업은 랜덤 하게 디스크에 기록해야 하기 때문에 상당한 자원이 소모된다. 그래서 이러한 부하를
줄이기 위해 대부분의 DBMS에는 변경된 데이터를 버퍼링 해두기 위해 InnoDb 버퍼 풀 과 같은 장치가 포함되어 있다.
하지만 이장치 만으로는 ACID를 보장 할수 없는데 이를 위해 변경된 내용을 순차적으로 디스크에 기록하는 로그 파일을 가지고 있다.
일반적으로 DBMS에서 로그라 하면 이 리두 로그를 지칭하는 경우가 많다.
MVCC(Multi Version ConCurrency Control)
MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는데 있다. 멀티 버전이라는 것은 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다는 의미이다.
만약 격리수준이 READ_UNCOMMITED 인 경우 에는 InnoDb 버퍼 풀 이나 데이터 파일로 부터 변경되지 않은 데이터를 읽어서 반환한다.
즉, 데이터가 커밋됐든 아니든 변경된 상태의 데이터를 반환한다. 그렇지 않고 READ_COMMITTED나 그 이상의 격리 수준인 경우에는 아직 커밋되지 않았기 때문에 InnoDB의 버퍼 풀이나 데이터 파일에 있는 내용 대신 변경되기 전의 내용을 보관하고 있는 언두 영역
의 데이터를 반환한다. 이러한 과정을 MVCC라고 표현한다.
트랜젝션이 길어지면 언두에서 관리하는 예전 데이터가 삭제되지 못하고 오랫동안 관리 되어야 하며, 자연히 언두 영역이 저장되는
시스템 테이블 스페이스의 공간이 많이 늘어나야 하는 상황이 발생할수도 있다.
커밋이 된다고 언두 영역의 백업 데이터가 항상 바로 삭제되는것은 아니다. 언두 영역을 필요로 하는 트랜젝션이 더이상 없을때 비로소 삭제된다.
잠금없는 일관된 읽기(Non-Locking consistent read)
InnoDb에서 격리수준이 SERIALIZABLE이 아닌 경우 순수한 SELECT작업은 다름 트랜젝션의 변경 작업과 관계없이 항상 잠금을 대기 하지 않고 바로 실행 된다.
특정 사용자가 레코드를 변경하고 커밋을 수행하지 않았다 하더라도 이 변경 트랜젝션이 다른 사용자의 SELECT 작업을 방해 하지 않는다.
이를 잠금없는 일관된 읽기 라고 포현하며, 변경되기 전의 데이터를 읽기위해 언두(UnDo)로그를 사용한다.
오랜시간 동안 활성상태인 트랜젝션에 위해 MySql서버가 느려지거나 문제가 발생할때가 잇는데, 바로 이러한 일관된 읽기를 위해
언두 로그를 삭제하지 못하고 계속 유지 하기 때문에 발생하는 문제다. 트랜젝션이 시작 됐다면 가능한 빨리 롤백이나 커밋을 통해 트랜젝션을 완료 하는것이 좋다.
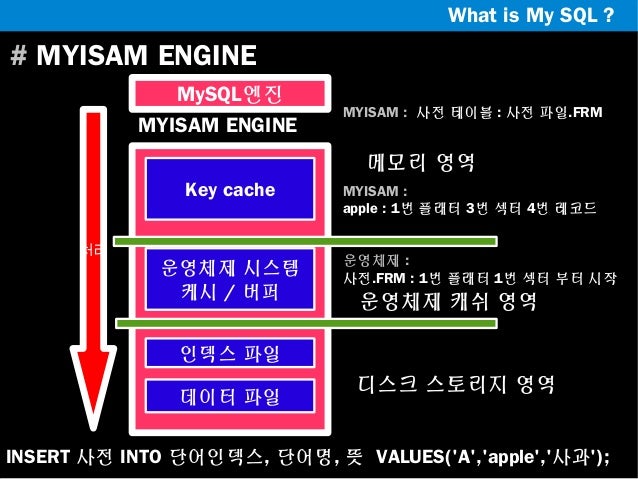
MyISAM 스토리지 엔진
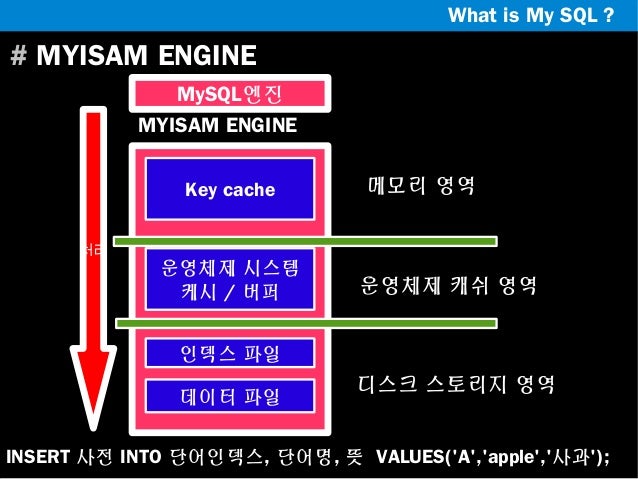
InnoDB의 버퍼풀의 비슷한 역활을 하는 것으로 MyISAM의 키캐시(Key cahe, 키버퍼)가 있다.
MyISAM 테이블의 인덱스는 키캐시를 이용해 디스크를 검색하지 않고 검색할 수 있으나 MyISAM 테이블의 데이터는 디스크로부터의 I/O를 해결해 줄만한 어떠한 캐시나 버퍼링 기능이 존재하지 않는다.
따라서 MyISAM 테이블의 데이터 읽기나 쓰기 작업은 항상 운영체제의 디스크로부터 읽고 쓰는 파일에 대한 캐시나 버퍼링 메커니즘을 가지고 있다. 운영체제가 사용할 메모리가 어느정도 보장이 되어야 가능함
MyISAM의 주로 사용되는 키캐시는 물리 메모리의 40% 이상을 넘지 않게 설정하는것이 좋다고한다.
MyISAM - 기본적인 특징
- 비활성화 할수 없는 기본 스토리지 엔진
- 데이터 저장에 실제적인 제한이 없음(파일시스템의 제한과 동일)
- 데이터를 매우 효율적으로 저장
- 빈번한 데이터 사용(Read)의 부하를 잘 소화
- B-tree,R-Tree, Full-Text 인덱스 지원
- 특정 인덱스에 대한 메모리 캐시지원(데이터는 캐시하지 않음)
- 데이터 압축 옵션 제공(압축하게 되면 ReadOnly가 되지만 디스크효율이 높아짐)
- 지리적 데이터 지원
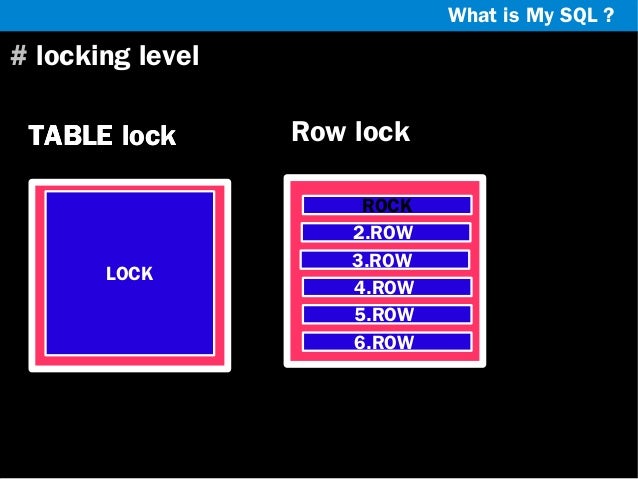
- 테이블 레벨의 락
- 트랜적션 미지원
- 백업 및 특정 시점으로의 복구 지원
- 적합한 사용처 : 트레픽이 많은 웹사이트(Read트래픽), 데이터 웨어하우스
InnoDB vs MyISAM
InnoDB의 특징
- 트랜젝션 지원
- 빈번한 쓰기, 수정, 삭제시 처리 능력
- 디스크, 전원 등의 장애 발생시 복구 성능
- 동시처리가 많은 환경에 적합
- Row Level Locking 지원
MyISAM의 특징
- 상대적으로 높은 성능
- 읽기 위주의 요청에 유리
- 테이블 단위 락킹
- Full Text Index를 지원하며 테이블 명시에 row count를 가지고 있기 때문에 count(*) 쿼리가 빠르다. 분석이나 로그등이 유리할듯
- 트랜잭션 지원이 없기 때문에 백업본 없으면 좃망...
CREATE Table 구문 실행시 ENGINE=InnoDB 혹은 ENGINE=MYISAM 으로 엔진을 지정할 수 있다
(5.5 버전부터는 기본 엔진이 InnoDB로 되어있다)
물론 메모리로 지정하여 사용할 수 있다.
NDB 클러스터 스토리지 엔진
NDB는 Network Database 의 줄미말로 네트워크를 통해 데이터 분산을 지원하는 스토리지 엔진입니다.
부하분산을 하기 위한 방법중 Replication보다는 비교적 최근에 나온 기능입니다.
NDB Cluster Storage Engine은 MySQL과는 별도의 프로세스로 동작해 클러스터링을 처리합니다. 결과적으로는 데이터 저장부분만 HA 형태로 운영이 가능한 아키텍처입니다.

NDB 클러스터의 특성
- 무공유 클러스터링 (데이터를 저장하는 스토리지도 분산되어 관리되기 때문에 하나의 데이터 저장소가 작동을 멈추어도 서비스의 영향이 없다.)
- 관리노드 ,데이타노드 ,SQL 노드로 구성되는데 3가지의 종류의 노드 모두 이중화 구현 가능함.
- 메모리 기반의 스토리지 엔진
- 자동화된 Fail-Over : 모든 구성 노드가 서로의 상태를 계속 체크하고 있어서 가능
- 분산된 데이터 저장소간의 동기방식(Sync) 복제 : 클러스터의 모든 데이터 노드에 변경된 데이타가 전달되어 완전히 저장되고 나서야 트랜젝션이 완료될수 있음을 의미함
- 온라인 스키마 변경 : 테이블에 컬럼이나 인덱스를 추가하면서 동시에 INSERT UPDATE 같은 DML 명령문 가능
NDB 클러스터의 아키텍처
- NDB 클러스터 노드의 종류 : 관리노드 ,데이터노드 ,SQL 노드로 구성 (이중화 될 수 있도록 구현됨 SPOF 방지를 위함)
- 관리노드 : NDB 클러스터의 전체적인 구저에 대한 정보를 다른 노드에 전달하거나 각 노드의 장애상황을 전파
- 데이터 노드 : NDB 클러스터의 핵심이자 즐러스터 전반적인 작업을 수행. 데이타를 저장하는 스토리지를 관리
- SQL 노드 : NDB 클러스터의 접속해 데이터를 읽고 쓰는 방법은 SQL 문법및 C 프로그래밍 언어를 이용해 데이터를 조작할 수도 있다. 전자를 SQL 노드라 하고 후자를 API 노드라고 한다.
클러스터 간의 복제구성
- MySQL 서버의 바이너리 로그만 클러스터간의 복제를 할수 없고 NDB 클러스터에는 2개 이상의 MySQL 서버가 동시에 쓰기와 읽기용 쿼리를 처리하게된다.
- 2개 이상의 MySQL 서버로부터 발생한 바이너리 로그를 동시에 발생시점순으로 하나의 슬레이브 MY-SQL 서버로 보낼수 없기 때문에 NDB 클러스터의 데이터 노드는 자기 자신에게 발생한 변경 내용을 SQL 노드로 피드백을 주며 자신의 바이너리 로그를 수정하고 이때 NDB Binlog injector 라는 스레드가 활성화 되는데 이 스레드가 바이너리 로그에 병합하는 역할을 담당한다.
NDB 클러스터의 성능
- SQL 노드의 갯수가 늘어날수록 성능이 선형적으로 증가한다.
- 하나의 SQL 노드에 너무 많은 요청이 발생하는 경우 SQL 노드가 제대로 처리하지 못하는 동시성 문제가 있다.
NDB 클러스터의 네트워크 영햘
- NDB 클러스터는 네트워크 기반으로 작동하기에 네트워크 전송속도가 쿼리 성능에 상당한 영향을 미친다.
- 성능이 민감한 서비스에 NDB 클러스터를 사용할 경우 네트워크 인터페이스를 일반적인 이더넷 카드가 아닌 SCI로 클러스터 구성을하기도 한다.
NDB 클러스터의 용도
- 필요한 저장 메모리의 양이 고정적인 주로 세션데이타를 관리하는 솔루션으로 사용
출처 - http://gliderwiki.org/wiki/163, http://www.slideshare.net/resoliwan/1-mysql-v1
'Major > Database' 카테고리의 다른 글
| MySql - JOIN (0) | 2016.04.13 |
|---|---|
| 데이터베이스 - 데이터 타입 (0) | 2015.11.26 |
| 데이터베이스 - 트랜잭션 (0) | 2015.11.26 |
| 데이터베이스 - SQL (0) | 2015.11.25 |
| 데이터베이스 - 관계 대수 (0) | 2015.11.25 |